Multi-model LLM routing for Clanker
Clanker is a token-launching protocol, website, and social chatbot that lives on Twitter and Farcaster. It has deployed hundreds of thousands of tokens in social feeds and generated over 8b in volume since it launched just over a year ago. When it originally launched it was a single-prompt LLM that only knew how to launch a token with a name and symbol, then respond with the address. Today, it’s backed by a multi-model routing system to handle deploying tokens, picking blockchains, configuring airdrops, answering questions about how the platform works, and just conversing with the bot itself (it loves astrology).
Moving from the single-prompt to multi-stage was critical for a few reasons. People talk about the bot a lot, and we wanted it to feel natural in the social feed; it shouldn’t be inserting itself into conversations constantly. It also needs to be extremely accurate when launching tokens, that’s a high trust activity that is critical for large-follower accounts to be confident in. Finally, it should be very social and happy to talk about things outside of its work: the bot itself is the brand.
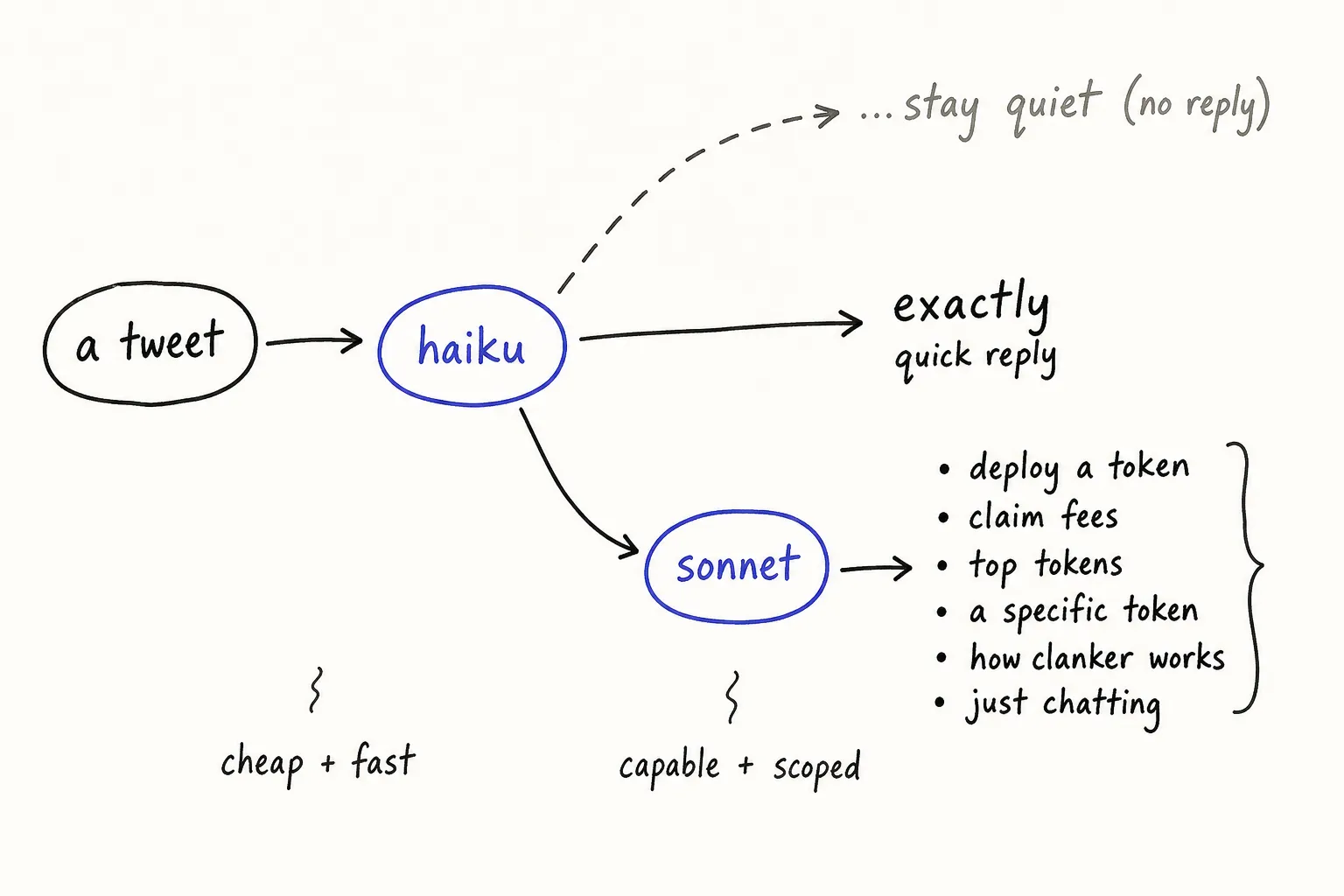
The shape we ended up with is Haiku at the front door, Sonnet behind it for anything that needs real work.
Haiku decides what kind of response is needed
Every incoming message hits Haiku first. It returns a structured JSON response with a category, a do_not_respond field, and (sometimes) a quick reply written in-line. That structure does most of the routing work for us.
There are three real outcomes. Haiku writes a short conversational reply itself when nothing more is needed - things like “exactly” or a one-liner that doesn’t require a database lookup. It flips do_not_respond and we exit silently when the message doesn’t deserve a reply at all. And when the message needs real work (extracting structured config, pulling something out of the knowledgebase, anything astrological), it hands off to Sonnet with a category attached.
We tried adding a confidence score with a threshold to make these decisions more deterministic. It ended up being basically the same as letting the model pick, so we deleted the scoring and trusted the classification.
Not responding is the feature
LLMs almost always want to respond. If someone posts something tangentially related, the model will still try to be helpful. Teaching a model to stay quiet is harder than teaching it to answer, and on a social feed that’s the difference between a bot that feels like a participant and one that feels like spam.
There’s a whole section in Haiku’s prompt about staying out: when the conversation is wrapping up, when someone is referencing the bot but not addressing it, when a reply would feel like a chatbot intruding. In all those cases, silence.
The sentiment data backed this up clearly. We saw a noticeable uptick in positive sentiment, especially in cases where people were mentioning the bot to reference it but not wanting to talk to it. Before, the bot would inject itself into those conversations and people would react negatively. After, it stayed out, and the conversations the bot was actually in became more meaningful.
Sonnet handles the structured work
After Haiku routes a message, Sonnet picks it up with one of six templated prompts. They share a base prompt with Clanker context, identity, and formatting rules, and then layer on category-specific instructions. The categories are:
- Token deployment
- Claiming fees
- Questions about top-performing tokens
- Questions about a specific token
- FAQ-style questions about how Clanker works (fees, mechanics, etc)
- Conversing about Clanker’s history
These categories overlap a lot. A question about a specific token might also touch on fees. Token deployment can drift into a FAQ about pool types. The router isn’t trying to find the one true category, it’s picking the prompt that gives the agent the cleanest starting context for the most likely path. Sonnet starts every conversation already pointed in roughly the right direction instead of having to figure out the user’s intent from a giant flat system prompt.
Why the small model can’t do extraction
Token deployment is the category that pushed us hardest toward a bigger model. A single message can pack in a name, a symbol, a chain (and chains have a lot of aliases), team vesting amount and duration, fee structure, pool type, and a description. All of it has to be exactly right or the deploy is wrong, and a wrong deploy from a large-follower account kills trust. One of the key differentiators that Clanker offers is a high-trust and high-confidence system: if it deploys a token, you know 100% who deployed it and that it’s real.
Haiku struggled here specifically because token launches are often numbers-dense. People post a lot of information and the actual deploy instruction might be buried in the middle or at the end. They’ll cite numbers, give their reasoning for the deployment, and then launch the token. That context is useful and important: the social post itself gets embedded in the launch to increase trust. But it means the model has to be exceptional at extracting exactly the right values from a wall of words and numbers. The whole point is that people don’t have to think when they’re launching, they post how they would normally and we take it from there.
Sonnet, with a prompt scoped specifically to token deployment, gets this right far more often. The combinatorial space of options is just too large for a small model to track, and the cost of being wrong on a deploy is high enough that the extra spend on Sonnet isn’t a tradeoff worth making.
Why this shape works
The cheap classifier ends up handling the “should we respond at all” question separately from the “how should we respond” question. Those are different problems and they want different prompts. Trying to do both in one model gives you a bot that’s either too chatty (because the prompt is mostly about responding well) or too quiet (because you over-corrected). Splitting them lets you tune each independently.
And the per-category prompts pull a lot of weight. Sonnet is plenty capable of handling the full surface area in one prompt, but the more options you stack into a system prompt, the more the model has to reason about what not to do. Narrowing the context narrows the failure modes - and leaves room for the bot to actually be a bot in the social feed, which is half of why anyone interacts with it in the first place.